Introdução
Se você acha que todo índice melhora a performance, este artigo pode mudar sua forma de programar. Vamos medir, comparar e entender quando um índice ajuda — e quando ele atrapalha. E, no processo, você vai conhecer a TFDIndexBuilder4D, uma classe fluente, declarativa e segura para criar e gerenciar índices na TFDMemTable sem repetição de código, com validações automáticas, logs e até exportação e importação em JSON.
Por que criar índices?
Um índice funciona como o sumário de um livro: sem ele, é preciso folhear página por página até encontrar o que procura; com ele, você vai direto ao ponto. No entanto, é importante lembrar que nem todo índice traz ganho de performance. Quando mal planejado, ele pode não só deixar as buscas mais lentas, como também prejudicar operações de escrita — já que cada inserção, atualização ou exclusão exige que o índice seja atualizado.
Tipos de degradação de performance em buscas
| Tipo de Degradação | O que significa | Exemplo prático* |
|---|---|---|
| Linear (O(n)) | O tempo de execução cresce na mesma proporção que o número de registros. | 1.000 registros → ~1.000 comparações 10.000 registros → ~10.000 comparações |
| Logarítmica (O(log n)) | O tempo aumenta lentamente, mesmo com grandes volumes de dados. | 1.000 registros → ~10 comparações 1.000.000 registros → ~20 comparações |
| Exponencial (O(2ⁿ)) | O tempo dobra a cada pequeno aumento de dados, tornando-se rapidamente inviável. | 10 elementos → 1.024 comparações 20 elementos → 1.048.576 comparações |
Nota: aqui usamos o termo comparações para representar de forma genérica qualquer operação necessária para localizar um dado — seja verificar um elemento em uma lista, percorrer nós de uma árvore ou avaliar condições em um índice. Essa métrica ajuda a entender a carga de trabalho que um algoritmo precisa executar para completar a busca.
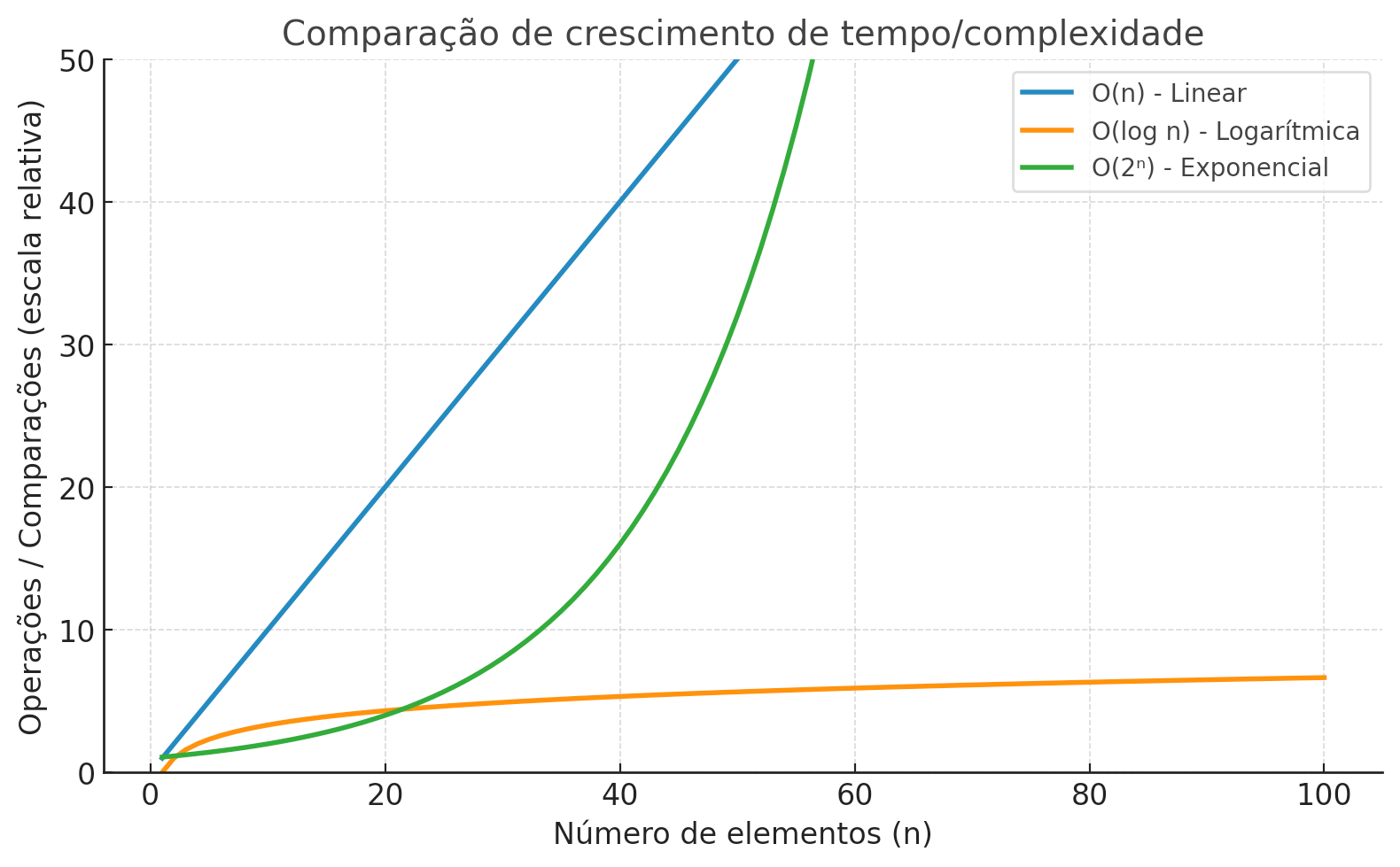
Um índice bem construído transforma uma busca linear em logarítmica. Essa diferença é o fator decisivo que mantém aplicações com grandes volumes de dados rápidas e responsivas.
Essas fórmulas — O(n), O(log n), O(2ⁿ) — fazem parte de um conceito chamado complexidade algorítmica, que mede o quanto um algoritmo é impactado quando lidamos com grandes volumes de dados. São formas de prever o comportamento de desempenho conforme os dados aumentam.
Por exemplo, enquanto um algoritmo linear precisa olhar item por item, um logarítmico divide para conquistar, avançando por saltos inteligentes.
Em um próximo artigo, vamos explorar como entender essas fórmulas de forma visual e prática, mesmo sem precisar saber matemática avançada.
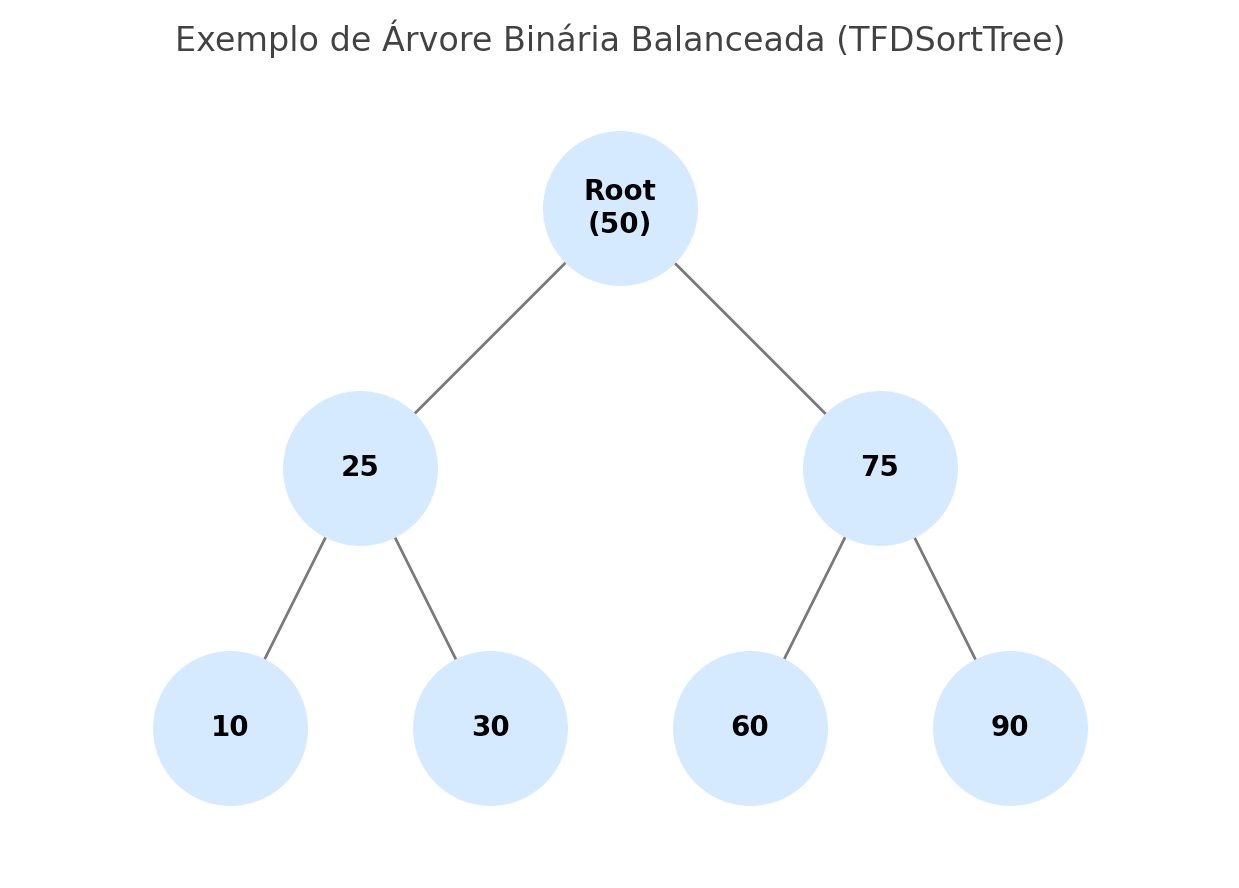
O que o TFDMemTable usa por baixo dos panos?
O TFDMemTable herda de TFDCustomMemTable e utiliza internamente uma estrutura chamada TFDSortTree — uma árvore binária balanceada que organiza os dados de forma a permitir buscas com complexidade O(log n).
Essa estrutura é eficiente para localizar registros rapidamente, mas a criação manual de índices sobre ela, no FireDAC, ainda exige código repetitivo, detalhamento de parâmetros e pouca flexibilidade, o que pode tornar o processo trabalhoso e propenso a erros.
Quando o índice atrapalha
- Muitos índices ativos: cada inserção, edição ou exclusão de dados exige atualização em todos os índices, o que impacta o desempenho de gravação.
- Baixa seletividade: campos booleanos ou com poucos valores não ajudam na busca, tendem a ser ineficazes para indexação: não aceleram buscas e ainda impõem custo adicional nas operações de escrita.
- Índices compostos mal planejados: a ordem dos campos importa.O primeiro campo define a efetividade real do índice.
Quando o índice pode ser mais lento que a busca linear?
Para demonstrar a importância da ordenação sequencial na performance de leitura, realizamos um experimento prático inserindo 5.000 registros em um TFDMemTable.
Os nomes seguiram um padrão simples: prefixo "Taro" seguido por um número sequencial — "Taro 1", "Taro 2", "Taro 3" … até "Taro 5000".
Embora seja um cenário artificial, ele é extremamente útil para ilustrar como a indexação pode melhorar ou prejudicar a busca de dados, dependendo da forma como os valores estão organizados.
1. O impacto da ordenação lexicográfica
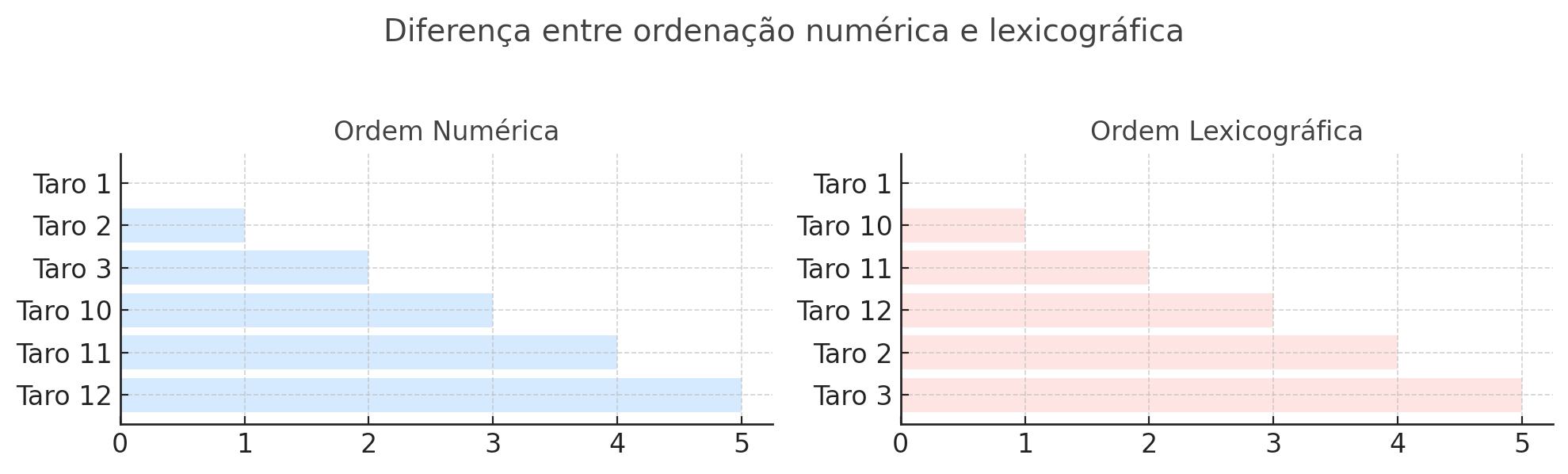
Ao ativar um índice no campo Name, o FireDAC utiliza o TFDSortTree — uma árvore binária balanceada — que ordena os registros de forma lexicográfica (como strings, e não como números). O resultado prático fica assim:
Taro 1
Taro 10
Taro 100
Taro 1000
Taro 1001
Taro 1002
Taro 1003
Taro 1004
Taro 1005
...
Note que "Taro 100" aparece antes de "Taro 2", pois na comparação de strings o caractere "1" vem antes de "2". Isso quebra completamente a sequência numérica esperada.
2. Medições reais
- Sem índice ativo
- Busca por
"Taro 500": ~6,234 ms - Os dados estavam na mesma ordem de inserção, permitindo que o mecanismo de busca percorresse linearmente até encontrar o valor.
- Busca por
- Com índice ativo
- Busca pelo mesmo valor: ~15,487 ms
- O dado foi reposicionado segundo a ordem lexicográfica, exigindo mais comparações na árvore do índice.
3. Por que isso acontece?
Quando os dados já estão naturalmente ordenados de acordo com o critério de busca (neste caso, inserção sequencial por nome), a busca linear pode ser muito eficiente — praticamente um Next até encontrar o item.
Ao ativar um índice, a ordenação lexicográfica reorganiza os registros de forma diferente da ordem numérica natural. Como consequência, a busca passa a seguir a estrutura da árvore, o que pode ser mais custoso nesse cenário específico.
4. Implicações práticas
Essa distinção é fundamental quando se usam strings como chave primária — especialmente identificadores como GUID ou UUID, que não são sequenciais nem numericamente comparáveis.
Nesses casos, o custo de ordenação e busca pode ser significativamente maior do que com uma chave inteira simples.
O experimento comprova que:
- o conteúdo dos dados
- e a forma como eles são organizados
são fatores determinantes na performance.
A indexação lexicográfica pode não se comportar como o esperado quando os valores aparentam conter números, mas são tratados como texto puro.
Em um próximo artigo, vamos explorar o uso de chaves primárias inteiras sequenciais e como elas podem impactar positivamente tanto a performance quanto a integridade dos dados.
GUID / UUID como chave primária: o problema silencioso
1. Ordenação
- GUIDs/UUIDs são strings longas (mesmo quando armazenados em formato binário, há 16 bytes).
- Quando a comparação é lexicográfica (como no
TFDSortTreedoTFDMemTable), cada busca exige comparar caractere a caractere até encontrar uma diferença — e isso é mais custoso que comparar um simples inteiro de 4 ou 8 bytes.
Eles são aleatórios do ponto de vista de ordenação, então não há “localidade” para aproveitar em buscas ou em cache de CPU. Isso significa que inserir ou buscar um GUID / UUID envolve mais saltos e comparações que um índice sequencial.
2. Diferença em relação a chaves inteiras
- Um inteiro sequencial preserva a proximidade física no índice: registros inseridos em sequência ficam juntos, facilitando leituras e buscas.
- GUIDs / UUIDs não preservam essa proximidade, causando mais fragmentação no índice.
3. Bancos como SQL Server mascaram o problema
- Bancos relacionais de alto nível como SQL Server, PostgreSQL, Oracle… usam otimizações internas: árvores B+, caches de páginas, estatísticas de distribuição, e podem armazenar GUIDs de forma binária para reduzir comparações.
- Mesmo assim, o uso de GUID / UUID como chave primária é desaconselhado em tabelas grandes com alto volume de escrita, justamente pelo custo de manutenção dos índices.
- Já no
TFDMemTablenão há essas otimizações sofisticadas, então o impacto aparece de forma mais evidente.
4. Conclusão técnica
- GUIDs / UUIDs custam mais para ordenar e buscar que inteiros sequenciais.
- O ganho de unicidade global vem com esse preço.
- Em estruturas como
TFDMemTable, que usam ordenação em árvore binária balanceada com comparação de strings, essa diferença de performance fica muito mais perceptível.
Como medir desempenho?
O Delphi oferece uma biblioteca nativa chamada System.Diagnostics, que inclui ferramentas poderosas — mas muitas vezes esquecidas — para medir performance com precisão.
Uma das joias dessa unit é a classe TStopwatch, que permite cronometrar trechos de código com alta resolução e extrema simplicidade:
uses System.Diagnostics;
var
Stopwatch: TStopwatch;
begin
Stopwatch := TStopwatch.StartNew;
FDMemTable.Locate('Name', 'Jonh', []);
Stopwatch.Stop;
ShowMessage(Format('Tempo:
%.3fms',Stopwatch.Elapsed.TotalMilliseconds]));
end;Esse exemplo mede quanto tempo leva para localizar um registro. Você pode adaptar facilmente para testar filtros, ordenações, inserções ou qualquer outro ponto crítico do seu código.
Medir é a única forma confiável de saber. O resto é opinião.
Em breve, traremos um artigo exclusivo sobre como usar a biblioteca System.Diagnostics para benchmarking real no Delphi, com foco em TStopwatch, TMemoryLeakMonitor, análise de picos de CPU, e outras ferramentas que muitos desenvolvedores desconhecem — mas que podem transformar seu processo de otimização.
Por que abstrair a criação de índices?
Criar índices manualmente em TFDMemTable exige:
- Saber a ordem dos campos;
- Gerar nomes exclusivos;
- Lidar com exceções por campos inexistentes;
- Repetir lógica em vários lugares.
Com o TFDIndexBuilder4D, você abstrai isso tudo:
- Usa fluent API para configurar;
- Evita nomes duplicados;
- Centraliza a lógica e permite reuso.
Mais que um atalho, é um facilitador seguro.
Reflexão: a classe parece mais complexa do que o necessário?
Essa dúvida é justa. Mas a TFDIndexBuilder4D não é apenas sobre facilitar a criação de índice. Ela permite:
- Criação dinâmica em resposta a eventos (ex: clicar em uma coluna da Grid cria um índice);
- Análise de performance com perfis de índice temporários;
- Exportação/importação de estruturas de índice (JSON);
- Validação automática de campos indexáveis;
- Simplificação de testes com milhares/milhões de registros;
Ela abstrai complexidade que, quando reaproveitada, reduz erros e repetições.
Principais recursos
- Criação fluente e encadeada;
- Suporte a múltiplos campos e ordenação ASC/DESC;
- Suporte a índices únicos (
soUnique); - JSON para serializar/deserializar índices;
- Validação de campos e tipos não indexáveis;
- Auto-nomeação de índice baseado nos campos;
- Safe delete (ignora se o índice não existir);
- Ativação/desativação de índice individual ou total;
- Callback de log para debug ou diagnóstico;
Benchmark Real com 1 Milhão de Registros
Durante testes de stress, criamos um índice composto (Name ASC + BirthDate ASC) sobre 1 milhão de registros em TFDMemTable, utilizando nossa arquitetura TSafeThread para manter a UI responsiva.
- Tempo total para criação do índice:
5,304 segundos; - Thread: paralela, sem travar interface.
Considerações:
TFDMemTablenão é otimizado para cenários massivos;- Mesmo assim, a criação dinâmica de índice se manteve estável e rápida;
TSafeThreadgarantiu execução segura com potencial para cancelamento e progresso;
🎁 Bônus: o post acompanha a unit TSafeThread, uma arquitetura robusta e reutilizável para tarefas assíncronas no Delphi, ideal para este tipo de operação. A TSafeThread será um dos assuntos que abordaremos no Tema Paralelismo, que em breve estará publicado.
Boas práticas e aprendizados do experimento
Durante a construção e execução deste experimento, surgiram pontos valiosos que merecem destaque. Eles ajudam a evitar armadilhas comuns e a extrair o máximo de performance do TFDMemTable com índices dinâmicos.
1. Desative o que não precisa estar ativo
Em operações com grande volume de dados, cada atualização extra na UI consome recursos. Se um TGrid estiver ligado porLiveBindings, a interface será redesenhada a cada inserção, mesmo que você não precise disso no momento.
O ideal é desligar o binding antes da operação e reativá-lo depois. O mesmo vale para EnableControls: desabilite antes de loops grandes e habilite só uma vez ao final.
2. Evite manutenção de índices durante cargas
Manter índices ativos enquanto insere milhares de registros é como reorganizar a estante a cada livro colocado. O fluxo mais eficiente é:
- Remover ou desativar os índices;
- Inserir todos os registros;
- Recriar os índices necessários ao final.
Essa prática reduz drasticamente o tempo total de carga.
3. Construa índices de forma inteligente
O método SmartBuildIndex é útil para evitar recriações desnecessárias. Se o índice já existe e está ativo, não há motivo para reconstruí-lo — isso economiza CPU e evita bloqueios em cenários concorrentes.
4. Use representações declarativas
Definir índices por string (Name:D;BirthDate:A) ou JSON oferece flexibilidade:
- Permite configuração externa sem recompilar o código;
- Facilita versionamento junto ao código-fonte;
- Dá ao usuário avançado a possibilidade de criar índices sob demanda.
Um schema JSON claro, com name, unique e fields (cada um com field e asc), mantém consistência e compatibilidade.
5. Valide a seletividade antes de criar
Índices são mais eficientes quando têm alta seletividade (muitos valores distintos). Campos como booleanos ou “ativo/inativo” raramente trazem ganho — o custo de manutenção pode superar o benefício. No experimento, calcular a frequência de valores antes de criar o índice ajudou a escolher a chave ideal.
6. Meça antes de decidir
A teoria ajuda, mas nada substitui medir no cenário real. Usamos TStopwatch para comparar buscas com e sem índice. Os resultados mostraram que, em alguns casos, a busca linear foi mais rápida que a busca indexada — algo que só descobrimos na prática.
7. Mantenha a UI responsiva com acesso seguro à Main Thread
A atualização de elementos visuais (progress bars, logs, labels) foi feita usando o mecanismo da TSafeThread, que garante acesso seguro à Main Thread. Isso evita erros de concorrência e mantém a aplicação fluida, mesmo durante operações pesadas.
Indexar é uma arte.
Mais índices não significam necessariamente mais velocidade. O segredo está em quando, onde e como usá-los.
Desligue o que não precisa estar ativo, carregue dados em lote, crie índices apenas quando fizer sentido e sempre valide com medições reais.

